I found myself wondering:
- what tricks are used when parsing strings?
- how much of a difference do they make?
- why?
To answer this, I needed numbers, so I threw together a manual parser and compared it with atoi.
Imagine my surprise when I found this:
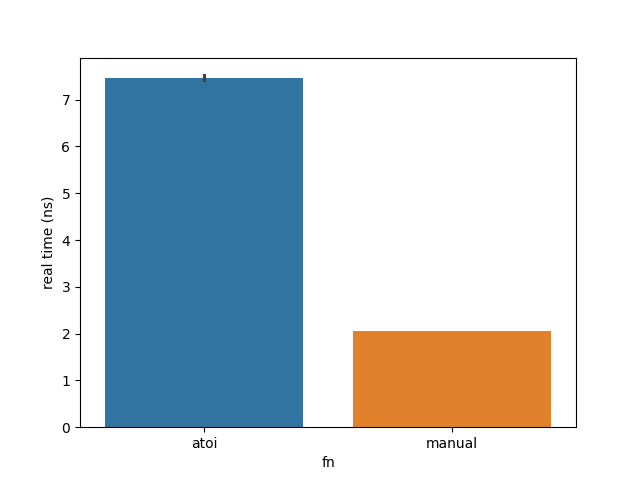
My naïve implementation is over 3 times faster than a mature function from the standard library shipped with MSVC 17.13.6. That seems incredibly unlikely. I must be doing something wrong.
Let’s throw strings full of exclamation marks at them:
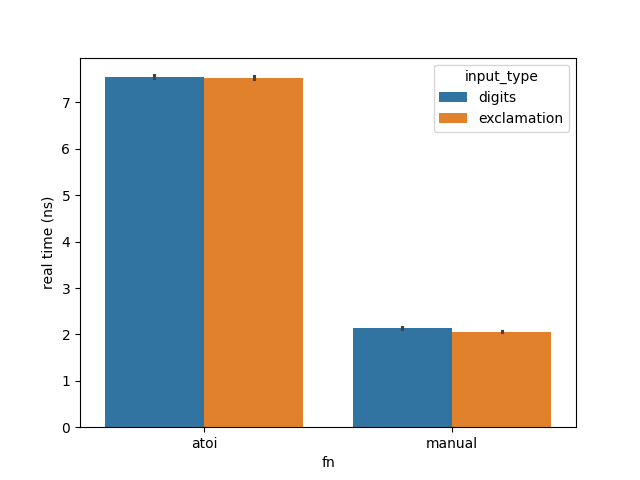
Not much difference. Something is amiss. Last time this happened, my value of N was too low. Let’s crank it up:
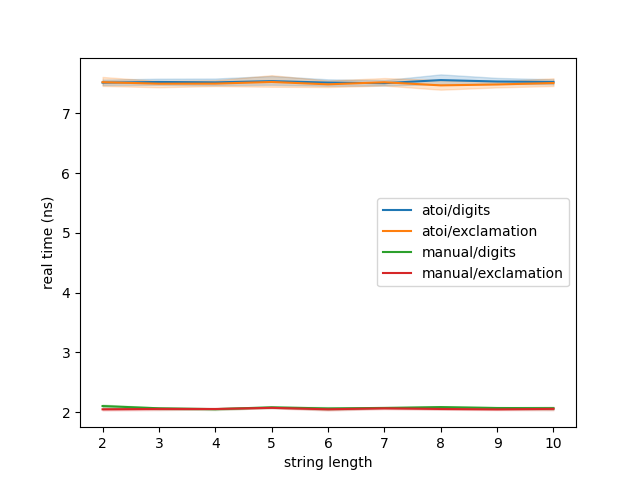
This is madness. I must be missing something. Let’s drop messing around with N for now to make trials quicker.
At this point, the right thing to do would be to profile it and see, but I’m doing this for fun. Playing around some more is what I want to do, so let’s roll with that.
Apples to Oranges
Perhaps it’s not a fair comparison; we should find out what edge cases and error handling requirements atoi has inflicted upon it.
atoineed not affect the value of the integer
expressionerrnoon an error. If the value of the result cannot be represented, the
behavior is undefined.The
atoifunction converts the initial portion of the string tointrepresentation.Except for the behavior on error, it is equivalent to
atoi: (int)strtol(nptr, (char **)NULL, 10)Returns
the converted value.
7.22.1 C11 N1570 [paraphrased]
No bueno. Maybe strol has answers:
The
strtolfunction converts the initial
portion of the string tolong intrepresentation.First, they decompose the input string into three parts: an initial, possibly empty, sequence of white-space characters (as specified by the
7.22.1.4 C11 N1570 [paraphrased]isspacefunction), a subject sequence resembling an integer represented in some radix determined by the value of base, and a final string of one or more unrecognized characters, including the terminating null character of the input string. Then, they attempt to convert the subject sequence to an
integer, and return the result.
atoi doesn’t have to concern itself with varying bases, only decimal is allowed. Its name stands for ASCII to Integer; Unicode can be ignored entirely.
There are two key differences, however:
- signs
- whitespace
Let’s add sign support first:
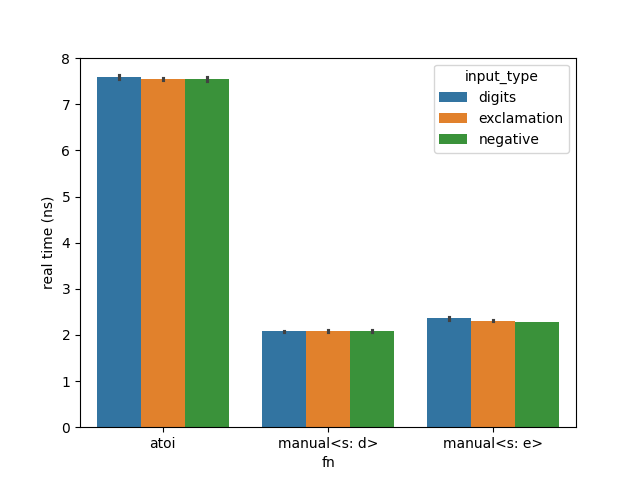
That’s not it. How about whitespace support?
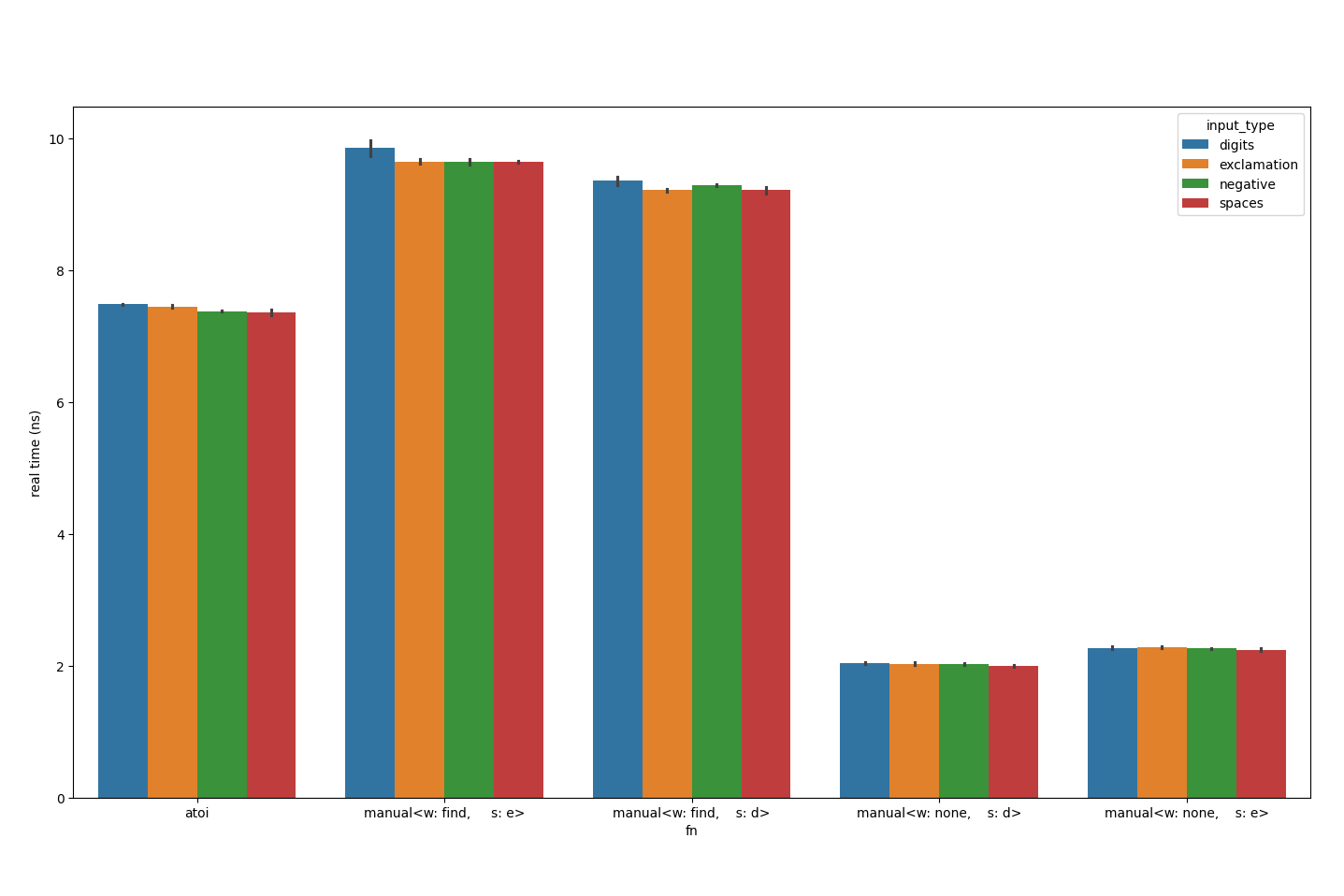
Now we’re talking.
Lemons to Oranges
Its name stands for ASCII to Integer; Unicode can be ignored entirely.
Famous last words.
ASCII is fairly well defined. Extended ASCII, that which uses the 8th bit, is not. It is a mess. A common interpretations for the 8-bit characters is ISO/IEC 8859-1 / Latin 1.
N411 [paraphrased]Bits | Hex | Identifier | Name ------|-----|------------|--------------- 10/00 | A0 | U+00A0 | NO-BREAK SPACE
The ubiquitous UTF-8 encodes that space in the same way. Countless other code pages likely do something else.
My implementation has a hard-coded set so far, whilst atoi uses isspace which in turns checks the locale.
Let’s switch ours to use isspace.
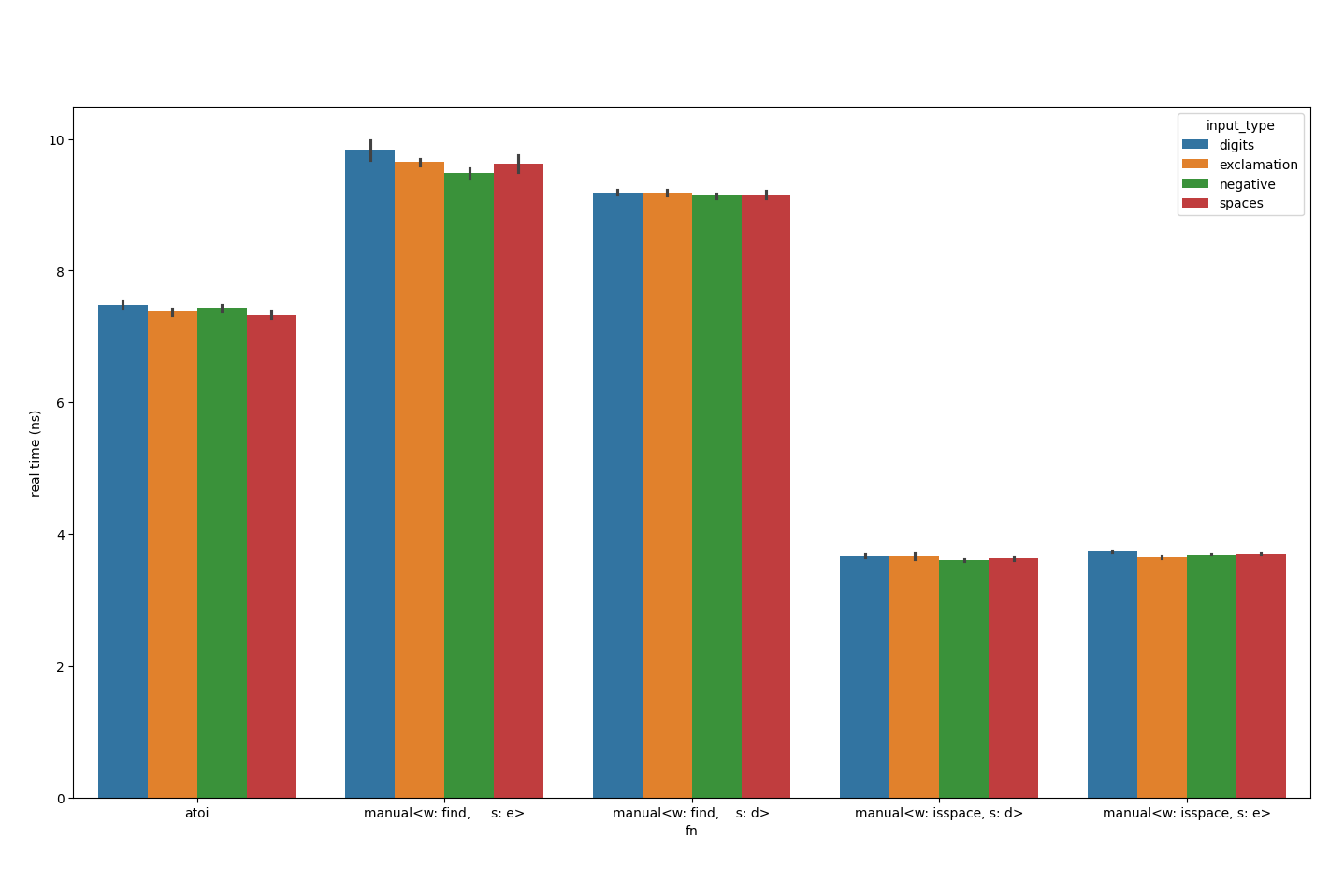
isspace is takes just under 4ns.Wait, it’s quicker using isspace? I expected slower, given it has more work to do. Here are the implementations:
while(isspace(str.front())) {
str.remove_prefix(1);
}constexpr std::array hard_coded_whitespace_chars = {
'\t',
'\n',
'\v',
'\f',
'\r',
' ',
};
const auto first_not_of = str.find_first_not_of(hard_coded_whitespace_chars.data());
str.remove_prefix(
std::min(
first_not_of,
str.size()));Profiling find_not_first_of difference shows reveals that ~77% of the time is spend inside of find_first_of is the slower case.
It appears to be doing a Boyer–Moore–Horspool-esk search. That makes sense for much larger strings, but most day-to-day numbers use less than 10 digits. Let’s swap this out for a simple loop, much like the isspace-based implementation:
while(std::ranges::any_of(
hard_coded_whitespace_chars,
[next = str.front()](const char whitespace)
{ return whitespace == next; }) {
str.remove_prefix(1);
}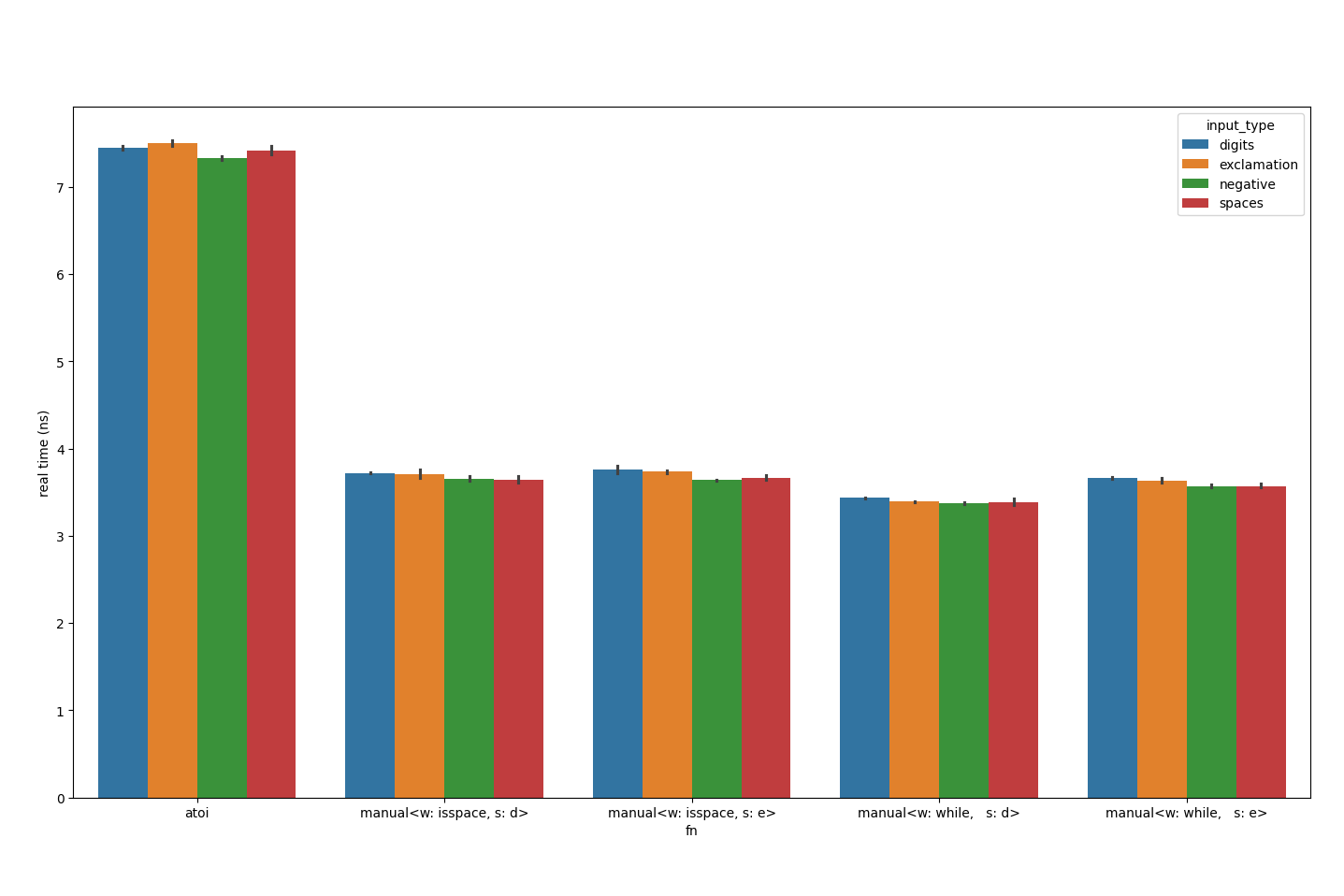
isspace version. It would seem to be roughly on-par. 40% of the time is spend searching skipping over whitespace characters still though.
Conveniently, a lot of the whitespace characters in the hard-coded locale are contiguous; perhaps we can use this to reduce the number of checks needed:
for (;
str.size() != 0
&& ((str.front() >= '\t' && str.front() <= '\r')
|| str.front() == ' ');
str.remove_prefix(1)));Let’s also skip the no-sign-support benchmark from now on, since a lot of use-cases are going to need it enabled and it’s not making a huge difference anyway.
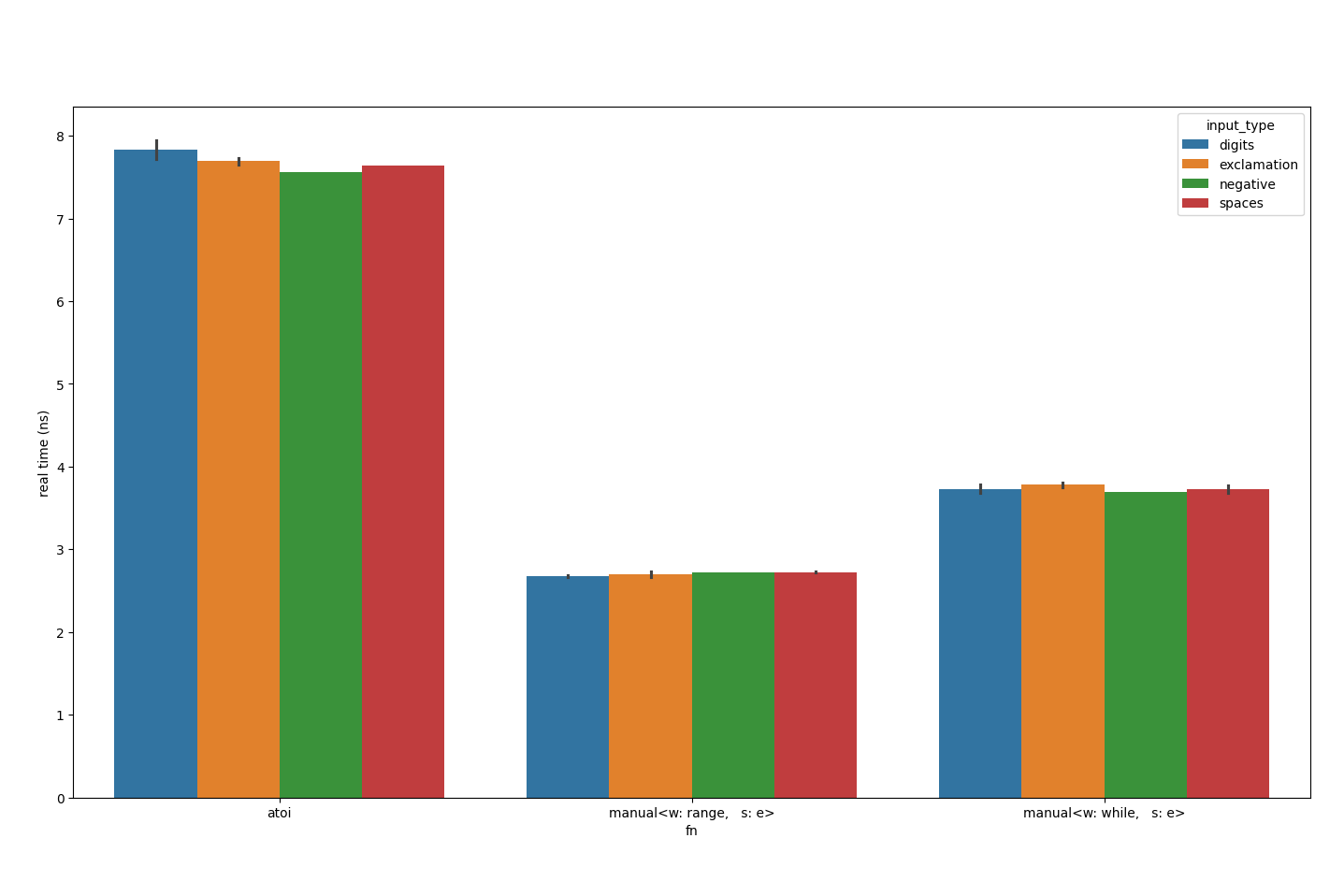
The condition for the range implementation isn’t pretty, which got me wondering: could I simplify it?
for (;
str.size() != 0
&& str.front() <= ' ';
str.remove_prefix(1));Much to my amazement, this is slower.
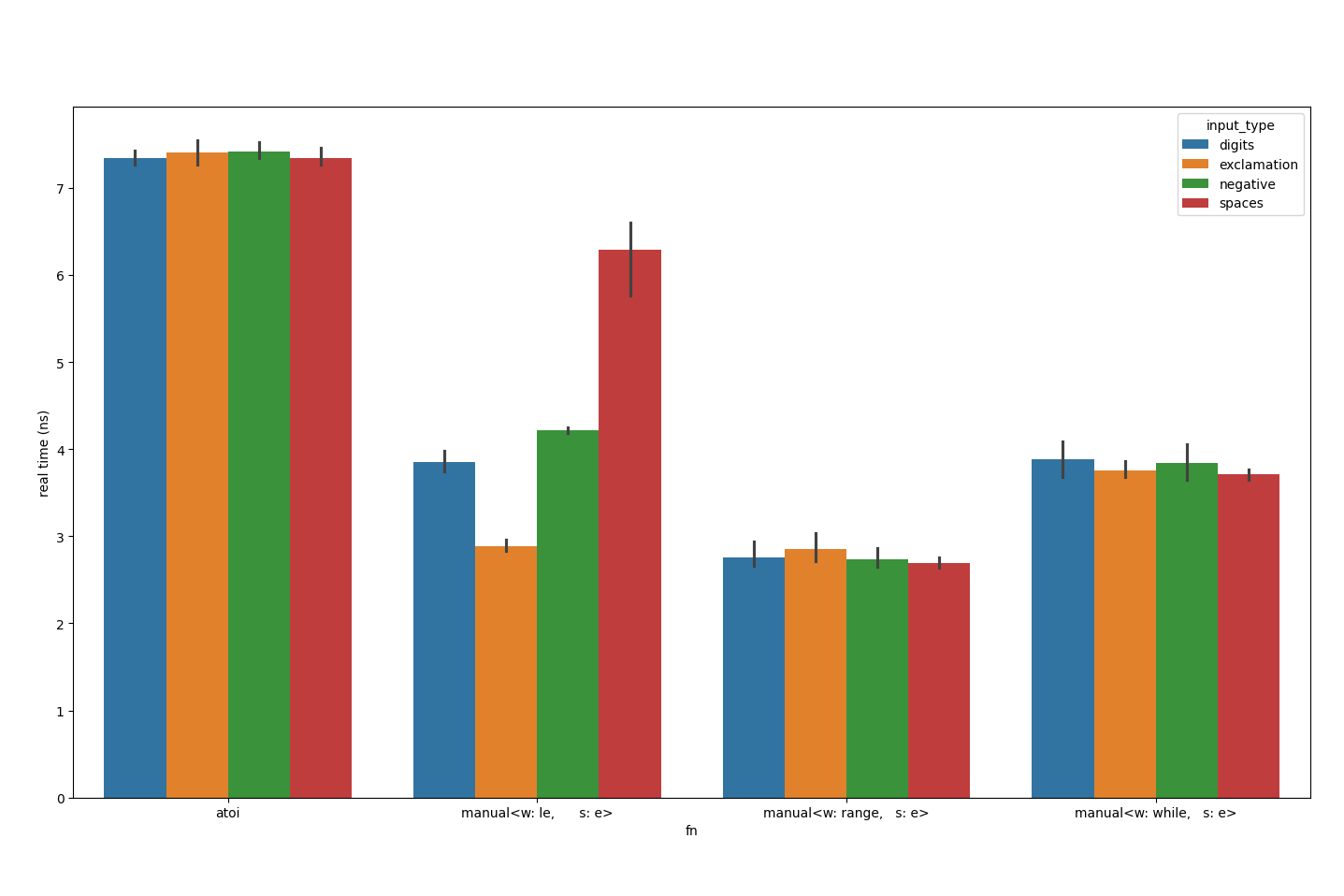
Substituting <= ' ' for < '+' yields similar results. I’ve been digging into this for months now, on and off, so thought it better to stop and look back. Perhaps I’ll come back to it.
Implications
Whilst not all would consider it a bottleneck, numeric parsing is pervasive. Some that might care include…
- Machine learning: it’s all the rage nowadays and those datasets can get pretty large. Multi-modal networks may care especially if they use numeric parsability as a heuristic for selection.
- High-frequency trading: every last microsecond counts. A tiny latency difference can be what makes a trade happen vs. not.
- Web APIs: servers want to be as responsive as possible, especially for high-traffic sites.
- Hyperscalers: saving some as seemingly-trivial as 1% can be a huge deal. Think about how much power those datacentres consume.
- Environmentalists: less cycles wasted, less power wasted, less machines needed.
- Library vendors: your client might care.
It’s also just wasteful. Suppose the data format you’re using doesn’t allow leading whitespace: if you use atoi, you’re checking for it needlessly. Similar things apply if the data has already been sanitised, or an encoding uses a fixed locale.
The only real cost is development time, which is non-trivial to say the least; atoi is that it’s readily available and well tested, allowing you to move on to other things.
There may be a middle ground though: given the naïve case is so much faster whilst still being easy to write, it may be some low-hanging fruit for a rainy day. There are also other implementations that have been more heavily optimised for specific use cases.
The biggest questions that remain in my mind though are:
- what other standard functions are doing needless work?
- is the cumulative impact significant?